hotchip33¶
第33届hotchip大会总结
samsung PIM¶
介绍了三星的存内计算架构。要理解它的架构,就需要先了解存内计算
什么是存内计算¶
冯诺依曼的架构是计算操作和内存操作分离的,尤其是现在主流的RISC架构,有专门的load/store指令负责内存操作,其他指令负责直接对寄存器进行计算。冯诺依曼架构在构建之初是假设处理器和内存速度很接近,但现在计算单元的性能随着摩尔定律一路飙升,而存储单元相较而言性能提升不大,因此,DRAM的性能已经成为了整个系统性能的重要瓶颈,也就是所谓的“内存墙”,这限制了处理器的计算性能和能效比。我们可以理解为CPU与内存之间的距离太远导致了内存墙,就像情侣异地恋情,因为举例限制了感情的发展,要想感情有突破,要么男的去女的城市,要么女的去男的城市。很显然,在AI这种数据密集的场景中,似乎把计算搬到离存储更近的地方更能提高整体性能和能效比。因此就有了存内计算。
存内计算(PIM processing-in-memory)可以突破内存瓶颈。尽管有很多不同的增加带宽的方法,但由于受到PCB布线,功耗及发热量,CPU接口数量等物理上的限制,这些方法很难有突破性的提升。 PIM旨在提升带宽密集型workloads(目前主要是AI领域)的性能,通过减少内存数据搬移来提升能量效率。
存内计算的本质是会使用模拟计算(如果不是使用模拟信号,那似乎和冯诺依曼架构也没什么区别吧),这也就意味着其目前只能应用在AI市场。而且存内计算技术想要突破,要在存储结构上做改进,使得存储单元更适合做计算。 存算一体目前精度不高,大概在8bit, 更适合端的嵌入式AI场景。
三星的Aquabolt-XL架构¶
- 一个16路的FP16 SIMD数组,支持FP16乘和加
- risc风格的32bit指令集,一共三种指令类型共计9条指令
- 指令参数可以是 GRF_A, GRF_B 向量寄存器,SRF标量寄存器或者bank row buffer.
三星提供了一整套的software stack来支持PIM.
graphcore colossue Mk2 IPU¶
众核的翘楚,目前Mk2 有1472个核,每个核带有624KiB的sram, 采用TSMC的7nm工艺,达到了823mm2 (这么大的面积,SRAM占了一半, 逻辑单元占了¼), 主频1.325GHz, 算力可达250Tflop/s
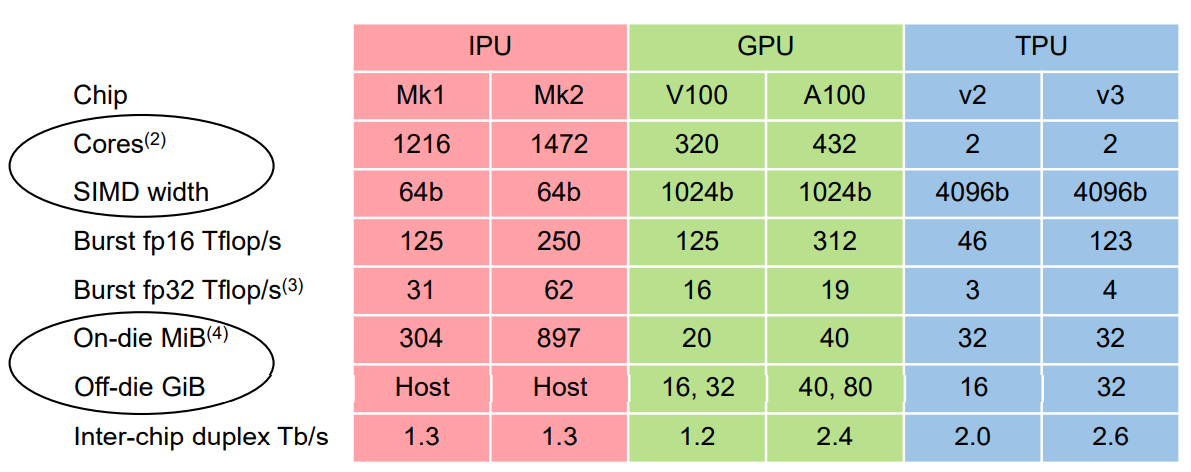
从上图的性能统计能够看出,graphcore的优势在于fp32的算力, 由于Mk2内部达到了897MiB的SRAM, 估计功耗表现要比A100好。
每个核被称为一个Tile, 除此之外,还有一个Exchange.文档中没有对tile及exchange做过多的介绍,也没法简单的通过文档获取一些设计信息。但我们能够看出tile不是一个简单的32bit的单发射或双发射CPU。 它有7个程序上下文,6个轮询的流水线slot, 每个slot执行⅙个clock.
主要有两个处理单元,一个MAIN, 一个AUX, main有自己的registerfile,名为MRF;AUX有一个名为ARF的registerfile。有一个负责调度slot的supervisor, supervisor通过执行RUN指令来调度节点,codelet执行完成后,以EXIT指令终止。节点以芯片时钟的⅙执行,看不到流水线。访存,分支,浮点,几乎所有的指令都需要一个周期执行完成。这样编译器就能比较轻松的预测codelet执行,这样就能够轻松的评估负载,做到负载均衡。
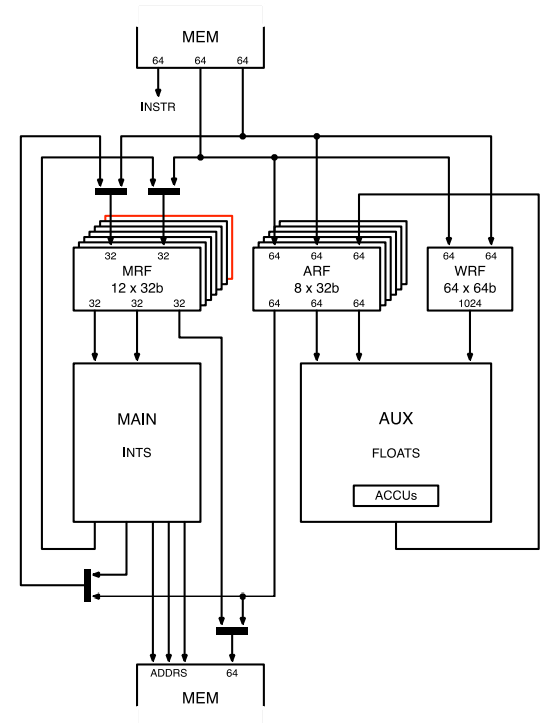
它有一个强大的浮点单元, 并且支持一些超越函数。
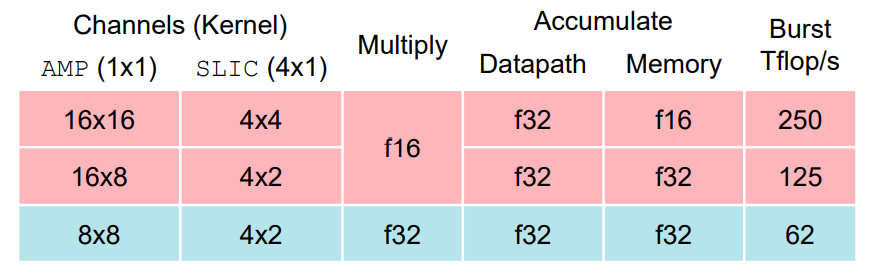
下面是它在拆分kernel时的策略, 可以看出,它还是拆分成很小的矩阵来进行运算,并且中间结果采用fp32进行累加,至于为什么这么拆分,单从上面简单的tile结构图上还很难分析清楚。
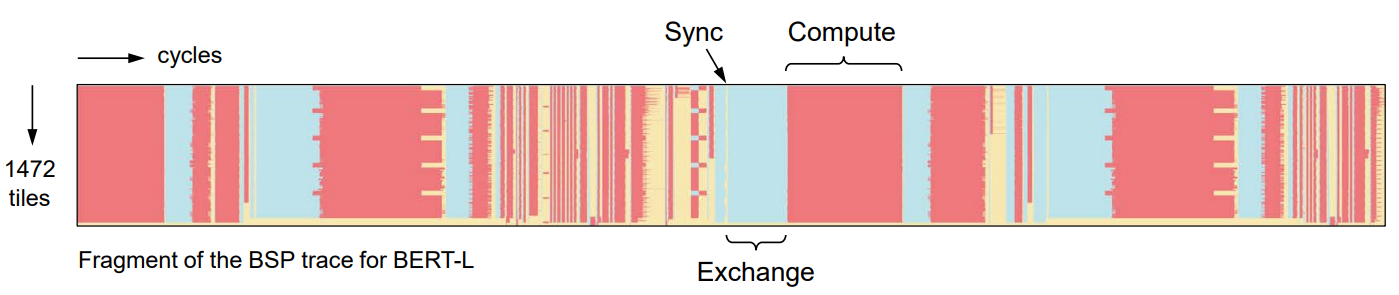
下面是运行bert-l 网络的时候的整体运行图,我们可以看出,所有tile都是按照sync,exchange,compute这三个状态进行循环,而且工具链对于整个网络的优化做的已经很好了,负载比较均衡。
graphcore给出了不用HBM(在存储单元上和DDR没有太大差异,主要是将内存和主芯片封在一个芯片里面,这样就跨越了封装对芯片引脚数目的限制,大大缩短了dram和主芯片直接的距离,同时采用3D堆叠技术,直接通过TSV打孔竖直堆叠在一起,高端的DDR也采取这种方式,当然这种方式对散热要求更高)的理由
- 内存容量决定了AI能做哪些事情,带宽只是限制了有多快
- GPU和TPU尝试使用HBM同时解决带宽和容量问题
- HBM非常昂贵,有容量限制,要多花100W美元以上
- IPU(graphcore称自家为IPU)使用SRAM来解决带宽问题,使用DDR来解决容量问题
- HBM的价格大概是DDR4的10倍($/GB), 40GB的HBM价格大概是一个reticle-sized处理器封装的3倍,IPU这种基于DDR的系统可以把省下来的钱用于生产更多的处理器
在DRAM中的权重和feature数据如何与SRAM进行配合,高效的进行运算呢?
猜想对于较小的模型,如果所有权重能够在sram中放下,并且保持一定的负载均衡,那么显然这是最快的方式。对于大型的模型,应该还是会存在DRAM与SRAM交互的情况。当然,这对于工具链是一个挑战。
如此巨大的芯片,一定有很多方法来控制关闭掉坏掉的部分。
除此之外,
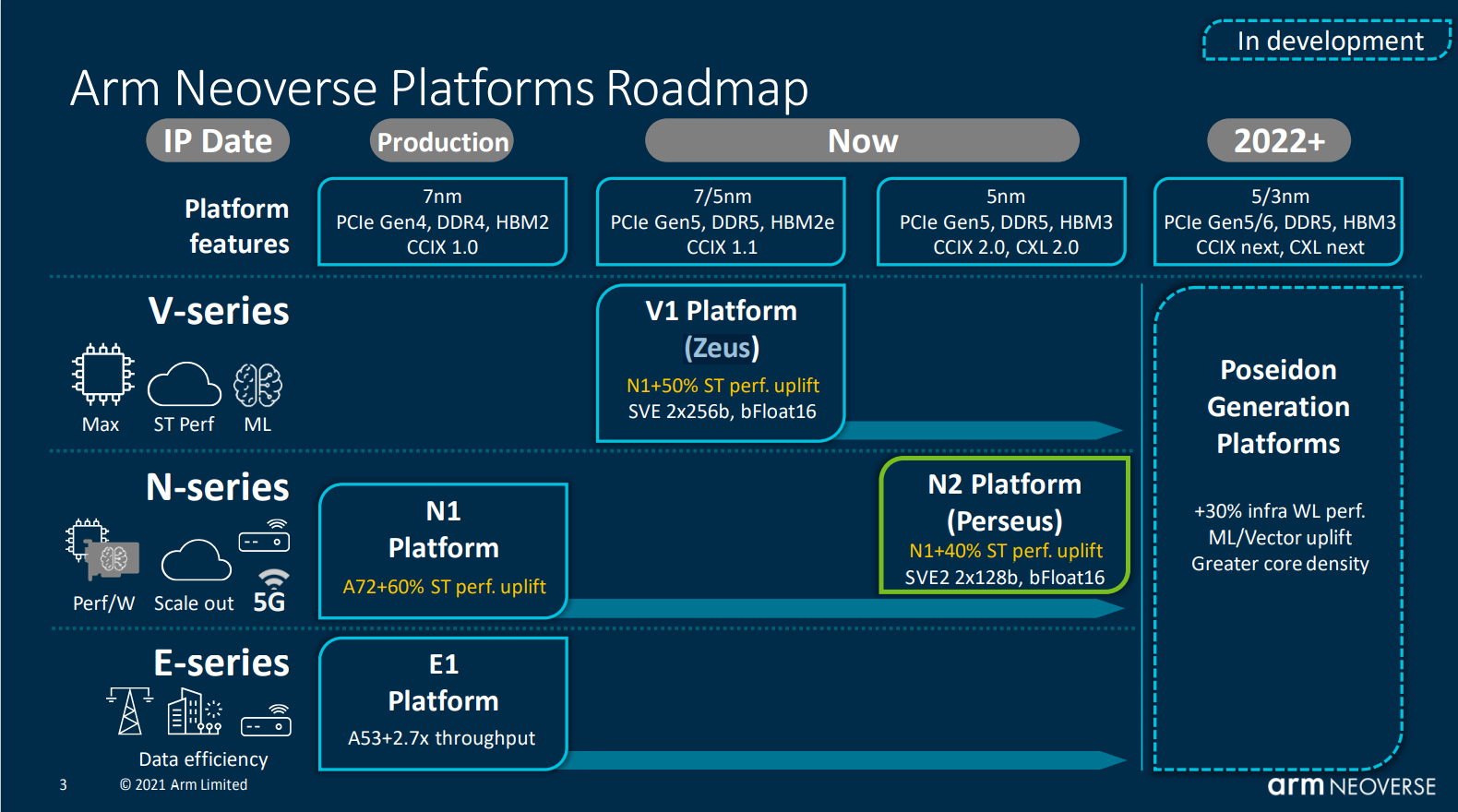
ARM neoverse¶
介绍了ARM第二代高性能基础架构CPU和系统IP。2018年arm推出了Neoverse处理器平台,旨在针对数据中心处理器市场,2019年搞定了N1版本,20年又发布了N2版本。
neoverse分为三大系列:
- V-serise 主打高性能,支持SVE 2x256b, 32-128 cores, 80-350W, ARMv9
- N-serise 性能,功耗,面积均衡, 12-36 cores, 30-80W, A72
- E-serise 强调能效,功耗和面积, 4-16 cores, 20-35W, A53
Intel Alder Lake¶
Alder Lake(美国华盛顿的一个名为奥尔德的湖, 不禁让人想到了中科院的雁栖湖) 是 Intel 21年最新发布的第12代CPU架构,这是一个大小核混合架构。大小核分别被成为Pcore和Ecore。从名字上就能看出,一个追求性能,一个追求能效比。猜测Intel使用大小核混合结构是为了适应更多的场景,不仅仅是桌面市场,在移动市场,Intel也想有更进一步的发展。不知道使用了Alder Lake的serface是不是能够销量大增。 新的混合架构在IO方面还支持PCIe Gen5和DDR5
Performance core¶
追求速度,强调低延迟,单线程性能。集成的矩阵引擎能够更好的处理AI场景,smart PM 控制,能够更好的对电源进行控制。 微架构名为Golden Cove
Efficient core¶
强调吞吐量,强调多任务多线程的总体性能。微架构名为Gracemont